Schnittstellenbeschreibung
Import der Kennzahlwerte
Abschnitt betitelt „Import der Kennzahlwerte“Der einfachste und schnellste Weg, Kennzahlwerte in maXzie zu importieren, ist die Schnittstelle per REST-API. Diese Schnittstelle ist sowohl beim Betrieb in der Cloud als auch On-Premises verfügbar. On-Premises gibt es noch alternativ den Import direkt aus der Datenbank.
Import per REST-API
Abschnitt betitelt „Import per REST-API“Für den Import von Leistungskennzahlwerten können CSV-Dateien, welche die benötigten Werte enthalten, an einen HTTP-REST-Endpunkt hochgeladen werden. maXzie bietet für jede konfigurierte Leistungskennzahl eine URL an, an welche Daten per HTTP-POST gesendet werden können. Die URL setzt sich folgendermaßen zusammen:
https://<maXzie_url>/api/v1/leistungskennzahlen/<UUID>/importDiese URL mit eingesetzer UUID kann in den Einstellungen der Leistungskennzahlen abgerufen werden.
Einstellungen der Leistungskennzahl
Abschnitt betitelt „Einstellungen der Leistungskennzahl“Kumulieren
Abschnitt betitelt „Kumulieren“Ist in der Definition der Leistungskennzahl der Punkt “Kumulieren” nicht aktiviert, müssen die bereits kumulierten Werte für jeden Zeitraum importiert werden.
Ist in der Definition der Leistungskennzahl der Punkt “Kumulieren” aktiviert, müssen für jeden Zeitraum die nicht-kumulierten Werte importiert werden. maXzie summiert dann die Werte für die einzelnen Zeiträume auf.
Passwort
Abschnitt betitelt „Passwort“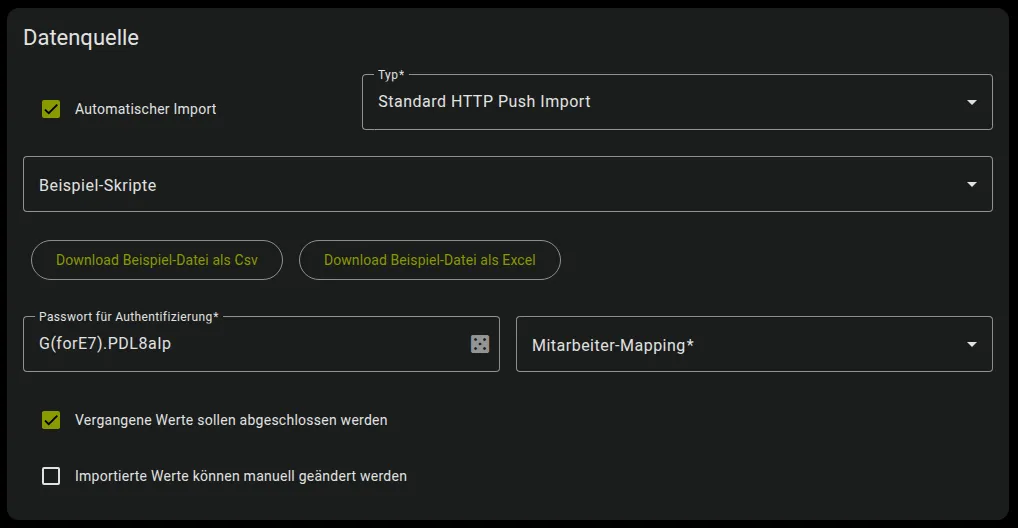
Das Passwort zur Aktivierung der Importe für jede LKZ-Datei kann unter der Option „Passwort für Authentifizierung“ erstellt werden.
Für ein erfolgreiches Importieren der Zahlen über die maXzie API müssen die in maXzie konfigurierten Passwörter für die jeweiligen Leistungskennzahlen in einem speziellen Header übergeben werden. Der Header hat dabei folgendes Format:
Authorization: LKZ <UUID> <Password>Dabei entspricht <UUID> dem eindeutigen Bezeichner und <Password> dem in maXzie konfigurierten Passwort der
entsprechenden Leistungskennzahl.
Mitarbeiter-Mapping
Abschnitt betitelt „Mitarbeiter-Mapping“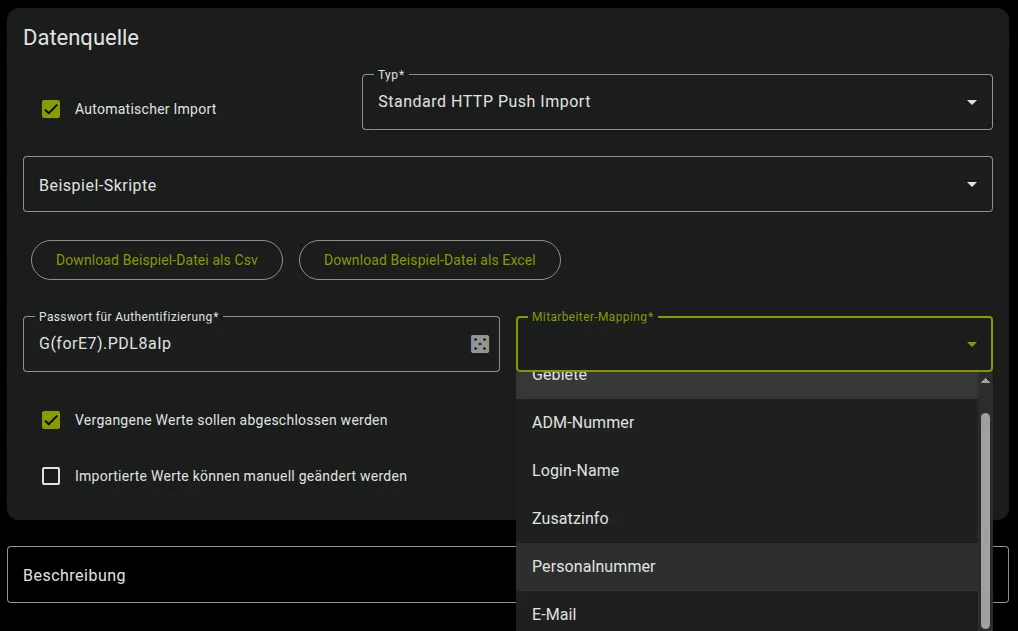
Die ausgewählte Einstellung „Mitarbeiter-Mapping“ dient als Schlüssel für den Import, um die Importwerte dem jeweiligen Mitarbeiter zuzuordnen. Die verschiedenen Mitarbeiterschlüssel sind bereits in den Mitarbeiter-Stammdaten hinterlegt.
Query-Parameter
Abschnitt betitelt „Query-Parameter“accumulation_timeframe
Abschnitt betitelt „accumulation_timeframe“Leerer Parameter
Abschnitt betitelt „Leerer Parameter“Der Query-Parameter accumulation_timeframe wird weggelassen, wenn
beim Import einzelne Zahlen pro Mitarbeiter und Zeitraum übertragen werden und beim Import keine Summen für die
einzelnen Zeiträume gebildet werden müssen.
Ohne den Query-Parameter accumulation_timeframe darf nur ein Wert pro Mitarbeiter und benötigtem Zeitraum vorliegen.
Wird in diesem Fall für einen benötigten Teilzeitraum für einen Mitarbeiter keine Zeile übertragen, werden
gegebenenfalls vorhandene Werte nicht verändert.
Gesetzter Parameter
Abschnitt betitelt „Gesetzter Parameter“Bei der Nutzung des Query-Parameters accumulation_timeframe setzt sich die URL folgendermaßen zusammen:
https://<maXzie_url>/api/v1/leistungskennzahlen/<UUID>/import?accumulation_timeframe=von--bisHierbei werden von und bis im ISO-8601-Format (JJJJ-MM-TT) angegeben, beispielsweise “2020-01-31”.
Durch den Query-Parameter accumulation_timeframe wird der Import auf den genannten Gesamtzeitraum eingeschränkt.
Summen werden auch für Teilzeiträume gebildet, die nur teilweise innerhalb des durch den Query-Parameter übergebenen
Gesamtzeitraums liegen (siehe auch
Beispielszenario 6). Wird
der Parameter accumulation_timeframe gesetzt und dabei für einen benötigten Teilzeitraum für einen Mitarbeiter oder
Gruppe keine Zeile übertragen, ergibt sich daraus die Summe 0.
skipRows
Abschnitt betitelt „skipRows“Um Zeilen am Anfang der übermittelten Datei zu überspringen, kann der Query-Parameter skipRows mit der Anzahl der zu
überspringenden Zeilen verwendet werden. Zum Beispiel kann bei vorhandener Kopfzeile mit Überschriften skipRows=1
genutzt werden. Wird der Parameter ausgelassen, werden keine Zeilen übersprungen.
CSV-Dateien
Abschnitt betitelt „CSV-Dateien“CSV-Dateien müssen die UTF-8-Zeichenkodierung ohne Signatur/BOM nutzen. Als Spaltentrennzeichen werden Semikolons
(“;”) und als Dezimaltrennzeichen Punkte (“.”) erwartet. Tausender-Trennzeichen werden nicht genutzt. Datumsangaben
werden im ISO-8601-Format (JJJJ-MM-TT) übertragen, beispielsweise “2020-04-01”.
Globale/Unternehmensweite Leistungskennzahlen
Abschnitt betitelt „Globale/Unternehmensweite Leistungskennzahlen“Bei Leistungskennzahlen ohne Zuordnung der Werte zu einzelnen Mitarbeitern werden folgende Spalten erwartet:
| Spalte | Titel | Beispiel |
|---|---|---|
| 1 | Datum | 2020-01-28 |
| 2 | Wert | 12345.67 |
Jeder Wert wird demjenigen Zeitraum zugeordnet, der das in Spalte 1 angegebene Datum enthält. Jedes Datum innerhalb dieses Zeitraums kann ohne Unterschied gleichermaßen verwendet werden.
Eine beispielhafte CSV-Datei würde damit folgendermaßen aussehen:
2020-01-31;47.02152020-02-28;4198.422020-03-31;0.00123Leistungskennzahlen mit Gruppenzuordnung
Abschnitt betitelt „Leistungskennzahlen mit Gruppenzuordnung“Bei Leistungskennzahlen mit Zuordnung der Werte zu Gruppen werden folgende Spalten erwartet:
| Spalte | Titel | Beispiel |
|---|---|---|
| 1 | Datum | 2020-01-28 |
| 2 | Gruppen Importschlüssel | gruppe_verkauf |
| 3 | Wert | 12345.67 |
Gruppen Importschlüssel werden in den ‘Gruppen’ Stammdaten eingegeben. Ein Wert wird derjenigen Gruppe zugeordnet, deren Gruppen Importschlüssel aus den Stammdaten dem in der Zeile übertragenen Gruppen Importschlüssel entspricht.
Eine beispielhafte CSV-Datei würde damit folgendermaßen aussehen:
2020-01-31;gruppe_verkauf;47.02152020-02-28;gruppe_innendienst;4198.422020-03-31;gruppe_aussendienst;0.00123Leistungskennzahlen mit Mitarbeiterzuordnung
Abschnitt betitelt „Leistungskennzahlen mit Mitarbeiterzuordnung“Bei Leistungskennzahlen mit Zuordnung der Werte zu Mitarbeitern werden folgende Spalten erwartet:
| Spalte | Titel | Beispiel |
|---|---|---|
| 1 | Datum | 2020-01-28 |
| 2 | Mitarbeiterschlüssel | P101 |
| 3 | Wert | 12345.67 |
Mitarbeiterschlüssel werden in den ‘Mitarbeiter’ Stammdaten eingegeben. Ein Wert wird demjenigen Mitarbeiter zugeordnet, dessen Mitarbeiterschlüssel aus den Stammdaten dem in der Zeile übertragenen Mitarbeiterschlüssel entspricht.
Eine beispielhafte CSV-Datei würde damit folgendermaßen aussehen:
2020-01-31;P2000284;47.02152020-02-28;P2487684;4198.422020-03-31;P0000001;0.00123Beispiel-Skripte
Abschnitt betitelt „Beispiel-Skripte“Der Import von Leistungskennzahlwerten über die maXzie-API kann beispielsweise folgendermaßen erfolgen:
-
Import mit curl unter Linux (Terminal)
Terminal-Fenster URL="https://<maXzie_url>/api/v1/leistungskennzahlen/<uuid>/import"HEADER="Authorization: LKZ <uuid> <password>"curl -k -X POST -H "Content-Type: text/csv" -H "$HEADER" --data-binary "@<import_file>" "$URL"maXzie stellt außerdem ein Beispielskript bereit, in dem
<UUID>und<password>direkt in das Leistungskennzahl Formular eingetragen werden.<UUID>und<password>werden nicht eingetragen, wenn die Leistungskennzahl nicht mindestens einmal gespeichert wurde.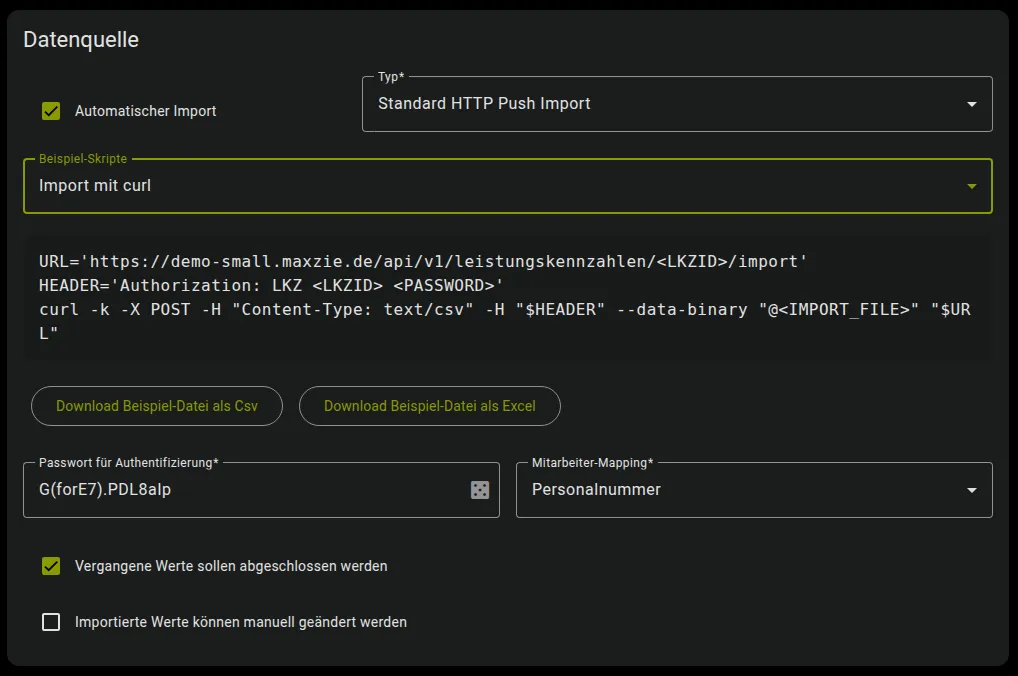
-
Import unter Windows (Powershell)
Terminal-Fenster [System.Net.ServicePointManager]::ServerCertificateValidationCallback = {$true}$AllProtocols = [System.Net.SecurityProtocolType]'Tls12'[System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols$url='https://<maXzie_url>/api/v1/leistungskennzahlen/<uuid>/import'$header=@{'Authorization'='LKZ <uuid> <password>'}$ep=Get-ExecutionPolicySet-ExecutionPolicy -ExecutionPolicy Unrestricted -Scope CurrentUserInvoke-WebRequest -Uri $url -Headers $header -ContentType 'text/csv' -Method POST -InFile <import_file>Set-ExecutionPolicy -ExecutionPolicy $ep -Scope CurrentUser
Sonstiges
Abschnitt betitelt „Sonstiges“Werden Werte für Zeiträume, die bereits mit Werten gefüllt sind, importiert, werden vorherige Werte für diesen Zeitraum und ggf. für diesen Mitarbeiter oder diese Gruppe überschrieben.
Beispiel-Szenarien
Abschnitt betitelt „Beispiel-Szenarien“Szenario 1: “Kumulieren” nicht gesetzt, “accumulation_timeframe” nicht gesetzt
Abschnitt betitelt „Szenario 1: “Kumulieren” nicht gesetzt, “accumulation_timeframe” nicht gesetzt“- Leistungskennzahl:
- Kumulieren: nicht gesetzt
- Reportperiode: Monat, startend am 1.1.2020
- Benötigter Parameter: Keiner (globale Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: nicht gesetzt
CSV-Datei:
2020-01-31;102020-02-28;152020-03-31;25Die aus dem Import resultierenden Werte in maXzie sind:
| Zeitraum | Wert |
|---|---|
| Januar 2020 | 10 |
| Februar 2020 | 15 |
| März 2020 | 25 |
Da Kumulieren für die Leistungskennzahl nicht gesetzt ist, werden die Werte so für jeden Monat einzeln übernommen und nicht kumuliert. Das bedeutet, der Wert 25 für den Zeitraum “März 2020” stellt nur den Wert für März dar.
Da accumulation_timeframe nicht gesetzt ist, darf für jeden Monat höchstens ein Wert vorhanden sein, da innerhalb der
Monate nicht kumuliert wird.
Szenario 2: “Kumulieren” gesetzt, accumulation_timeframe nicht gesetzt
Abschnitt betitelt „Szenario 2: “Kumulieren” gesetzt, accumulation_timeframe nicht gesetzt“- Leistungskennzahl:
- Kumulieren: gesetzt
- Reportperiode: Monat, startend am 1.1.2020
- Benötigter Parameter: Keiner (globale Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: nicht gesetzt
CSV-Datei:
2020-01-31;102020-02-28;152020-03-31;25Die aus dem Import resultierenden Werte in maXzie sind:
| Zeitraum | Wert |
|---|---|
| Januar 2020 | 10 |
| Februar 2020 | 25 |
| März 2020 | 50 |
Da Kumulieren für die Leistungskennzahl gesetzt ist, werden die Werte von maXzie von Monat zu Monat kumuliert. Das bedeutet, dass der Wert 50 für den “März 2020” alle vorherigen Zeiträume (Januar + Februar + März) enthält.
Da accumulation_timeframe nicht gesetzt ist, darf für jeden Monat höchstens ein Wert vorhanden sein, da innerhalb der
Monate nicht kumuliert wird.
Szenario 3: “Kumulieren” nicht gesetzt, accumulation_timeframe gesetzt
Abschnitt betitelt „Szenario 3: “Kumulieren” nicht gesetzt, accumulation_timeframe gesetzt“- Leistungskennzahl:
- Kumulieren: nicht gesetzt
- Reportperiode: Monat, startend am 1.1.2020
- Benötigter Parameter: Keiner (globale Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: gesetzt als
- von: 2020-01-01
- bis: 2020-03-31
- accumulation_timeframe: gesetzt als
Diese Konfiguration wird momentan nicht unterstützt.
Szenario 4: “Kumulieren” gesetzt, accumulation_timeframe gesetzt
Abschnitt betitelt „Szenario 4: “Kumulieren” gesetzt, accumulation_timeframe gesetzt“- Leistungskennzahl:
- Kumulieren: gesetzt
- Reportperiode: Monat, startend am 1.1.2020
- Benötigter Parameter: Keiner (globale Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: gesetzt als
- von: 2020-01-01
- bis: 2020-03-31
- accumulation_timeframe: gesetzt als
CSV-Datei:
2020-01-15;32020-01-20;72020-02-10;112020-02-23;42020-03-31;25Die aus dem Import resultierenden Werte in maXzie sind:
| Zeitraum | Wert |
|---|---|
| Januar 2020 | 10 |
| Februar 2020 | 25 |
| März 2020 | 50 |
Da Kumulieren für die Leistungskennzahl gesetzt ist, werden die Werte von maXzie von Monat zu Monat kumuliert. Das bedeutet, dass der Wert 50 für den “März 2020” alle vorherigen Zeiträume (Januar + Februar + März) enthält.
Da accumulation_timeframe gesetzt ist, werden innerhalb der einzelnen Monate die Werte aufaddiert.
Szenario 5: “Kumulieren” gesetzt, accumulation_timeframe gesetzt, Leistungskennzahl mitarbeiterbezogen
Abschnitt betitelt „Szenario 5: “Kumulieren” gesetzt, accumulation_timeframe gesetzt, Leistungskennzahl mitarbeiterbezogen“- Leistungskennzahl:
- Kumulieren: gesetzt
- Reportperiode: Monat, startend am 1.1.2020
- Benötigter Parameter: Mitarbeiter (mitarbeiterbezogene Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: gesetzt als
- von: 2020-01-01
- bis: 2020-03-31
- accumulation_timeframe: gesetzt als
CSV-Datei:
2020-01-15;P101;32020-01-20;P101;72020-02-10;P101;112020-02-23;P101;42020-03-31;P101;252020-01-11;P102;32020-01-25;P102;22020-02-04;P102;62020-02-21;P102;4Die aus dem Import resultierenden Werte in maXzie sind:
- für den Mitarbeitenden P101:
| Zeitraum | Wert |
|---|---|
| Januar 2020 | 10 |
| Februar 2020 | 25 |
| März 2020 | 50 |
- für den Mitarbeitenden P102:
| Zeitraum | Wert |
|---|---|
| Januar 2020 | 5 |
| Februar 2020 | 15 |
| März 2020 | - |
Da Kumulieren für die Leistungskennzahl gesetzt ist, werden die Werte von maXzie von Monat zu Monat kumuliert. Das bedeutet, dass der Wert 50 für den Mitarbeiter “P101” für den Zeitraum “März 2020” alle vorherigen Zeiträume (Januar, Februar, März) enthält.
Da accumulation_timeframe gesetzt ist, werden innerhalb der einzelnen Monate die Werte aufaddiert.
Die Reihenfolge der Zeilen in der CSV-Datei ist willkürlich gewählt. Da für den März die Werte für den Mitarbeitenden “P102” fehlen, werden hier auch keine Werte importiert und der Wert in maXzie wird leer gesetzt. Werden im April die ersten Werte importiert und ist bei der Leistungskennzahl der Punkt “Vergangene Werte sollen abgeschlossen werden” aktiviert, wird für den März eine Null als Wert gesetzt.
[[szenario_with_weeks]]
Szenario 6: “Kumulieren” gesetzt, accumulation_timeframe gesetzt, wöchentliche Reportperiode
Abschnitt betitelt „Szenario 6: “Kumulieren” gesetzt, accumulation_timeframe gesetzt, wöchentliche Reportperiode“- Leistungskennzahl:
- Kumulieren: gesetzt
- Reportperiode: Wochen, startend am 6.1.2020 (Montag)
- Benötigter Parameter: Keiner (globale Leistungskennzahl)
- Query-Parameter:
- accumulation_timeframe: gesetzt als
- von: 2020-01-01
- bis: 2020-02-29
- accumulation_timeframe: gesetzt als
CSV-Datei:
2020-01-15;32020-01-17;32020-01-21;42020-02-10;52020-02-13;62020-02-23;32020-02-28;1Die aus dem Import resultierenden Werte in maXzie sind:
| Zeitraum | Wert |
|---|---|
| KW1 2020 (6.1.2020-12.1.) | 0 |
| KW2 2020 (13.1.2020-19.1.) | 6 |
| KW3 2020 (20.1.2020-26.1.) | 10 |
| KW4 2020 (27.1.2020-2.2.) | 10 |
| KW5 2020 (3.2.2020-9.2.) | 10 |
| KW6 2020 (10.2.2020-16.2.) | 21 |
| KW7 2020 (17.2.2020-23.2.) | 24 |
| KW8 2020 (24.2.2020-01.3.) | 25 |
Da Kumulieren für die Leistungskennzahl gesetzt ist, werden die Werte von maXzie von Woche zu Woche kumuliert.
Da accumulation_timeframe gesetzt ist, werden innerhalb der einzelnen Wochen die Werte aufaddiert (z.B. werden Werte
von 2020-01-15 und 2020-01-17 für den Wert von KW2 aufsummiert).
Da KW8 (24.2.-1.3) teilweise im accumulation_timeframe (1.1.2020-29.2.2020) liegt, werden auch für diesen Zeitraum
Werte importiert.
Beispiel für ein Python Skript für einen Import aus einer PostgreSQL Datenbank
Abschnitt betitelt „Beispiel für ein Python Skript für einen Import aus einer PostgreSQL Datenbank“#!/usr/bin/python3
import psycopg2import datetimefrom psycopg2.extensions import AsIsfrom requests.auth import HTTPBasicAuthimport csvimport requests
host = "{Host}"user = "{Benutzer}"database = "{Datenbankname}"password = "{Passwort}"url = "https://kunde.maxzie.de/api/v1/leistungskennzahlen/{Leistungskennzahl-ID}/import"token = "{Token}"aktuellesDat = datetime.datetime(2021, 1, 17)
def get_CsvAusPostgresDatenbank(): connection = None try: connection = psycopg2.connect( database=database, user=user, host=host, password=password) connection.set_session( isolation_level=psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE) cursor = connection.cursor() sql_select = """SELECT personalnummer, auftragsdatum, SUM(umsatz) FROM Auftragseingang WHERE EXTRACT(YEAR FROM auftragsdatum) = %(year)s AND EXTRACT(MONTH FROM auftragsdatum) = %(month)s GROUP BY personalnummer, auftragsdatum""" cursor.execute( sql_select, {"year": aktuellesDat.year, "month": aktuellesDat.month}) csvLines = [] if cursor.rowcount > 0: rows = cursor.fetchall() for row in rows: line = row[1].strftime("%Y-%m-%d") + ";" + row[0] + ";" + str(row[2]) csvLines.append(line) finally: if connection is not None: connection.close()
return csvLines
def main(): csvLines = get_CsvAusPostgresDatenbank() response = requests.post( url=url, data="\r\n".join(csvLines), headers={"Authorization": "LKZ {Leistungskennzahl-ID} " + token}) print(response) print(response.text)
if __name__ == '__main__': main()Import aus Microsoft SQL Server oder PostgreSQL
Abschnitt betitelt „Import aus Microsoft SQL Server oder PostgreSQL“Der Import von Leistungskennzahlwerten wird über SQL-Abfragen realisiert, die in regelmäßigen Abständen von maXzie in der Datenbank des Kunden ausgeführt werden und dort die von maXzie benötigten Werte auslesen.
Abfragen und die Zeitpunkte, zu denen die Abfragen von maXzie ausgeführt werden sollen, werden in der Web-Oberfläche für jede Leistungskennzahl einzeln in der Einstellungsseite der betroffenen Leistungskennzahl konfiguriert. Hierzu muss zunächst der automatische Import aktiviert und der Import aus Microsoft SQL Server bzw. “PostgreSQL” ausgewählt werden. Daraufhin stehen die Eingabefelder “Trigger”, “URL”, “Benutzer”, “Passwort” und “Abfrage” zur Verfügung.
Konfigurationsfelder “URL”, “Benutzer” und “Passwort”
Abschnitt betitelt „Konfigurationsfelder “URL”, “Benutzer” und “Passwort”“Die Informationen der Konfigurationsfelder “URL”, “Benutzer” und “Passwort” ermöglichen maXzie den Zugriff auf eine bestimmte Datenbank des Kunden. Beispielhafte Angaben für “URL” sind:
- Für SQL Server:
jdbc:sqlserver://10.1.0.2:1433;DatabaseName=customerdata - Für PostgreSQL:
jdbc:postgresql://10.1.0.2:5432/customerdata
Ggf. sind z.B. für Verschlüsselung der Datenübertragung weitere Parameter sinnvoll. Weitere Informationen finden sich in der Dokumentation des Datenbanksystems.
Konfigurationsfeld “Trigger”
Abschnitt betitelt „Konfigurationsfeld “Trigger”“Das Konfigurationsfeld “Trigger” bestimmt Zeitpunkte und Frequenz der Datenbankabfrage. Hier werden Cron-Ausdrücke verwendet. Beispielhafte Werte sind:
- Import jede Nacht um 5 Uhr:
* * 5 * * * - Import jeden Sonntag um 6 Uhr:
* * 6 * * 7 - Import zu jeder vollen Stunde:
0 0 * * * *
Weitere Informationen und Beispiele finden Sie unter https://docs.spring.io/spring-framework/docs/current/javadoc-api/org/springframework/scheduling/support/CronExpression.html#parse-java.lang.String-
Konfigurationsfeld “Abfrage”
Abschnitt betitelt „Konfigurationsfeld “Abfrage”“Im Konfigurationsfeld “Abfrage” muss eine SQL-SELECT-Abfrage hinterlegt werden, die in der angegebenen Datenbank des Kunden ausgeführt wird. Diese Abfrage hat die Aufgabe, die von maXzie benötigten Werte auszulesen. Die Zeiträume, für die Werte benötigt werden, sind in einer von maXzie erzeugten temporären Tabelle enthalten. Die Abfrage muss die sonstigen Tabellen der Datenbank mit dieser temporären Tabelle verknüpfen, um die benötigten Werte als Ergebnis zu erzeugen.
Diese temporäre Tabelle mit den Zeiträumen der benötigten Werte wird vor der Ausführung der angegebenen Abfrage erzeugt und existiert nur innerhalb der Transaktion, in der die angegebene Abfrage durchgeführt wird. Der Name der temporären Tabelle wird durch maXzie festgelegt, der Platzhalter #neededValues wird zum Zeitpunkt der Abfrage durch den Namen der temporären Tabelle ersetzt. Die Struktur dieser Tabelle ist folgende (wird automatisch von maXzie angelegt):
CREATE TABLE #neededValues ( leistungskennzahlwert_id CHAR(36) NOT NULL, subjectId VARCHAR(255), fromYear INTEGER NOT NULL, fromMonth INTEGER NOT NULL, fromDay INTEGER NOT NULL, toYear INTEGER NOT NULL, toMonth INTEGER NOT NULL, toDay INTEGER NOT NULL);subjectId identifiziert hier einen Mitarbeiter oder eine Gruppe, wenn die geforderten Werte sich auf einen einzelnen
Mitarbeiter oder eine einzelne Gruppe beziehen sollen. Die nötigen Felder müssen bei der Einrichtung von der {ni}
konfiguriert werden und stehen dann in den Stammdatenformularen zur Verfügung. Bei der Konfiguration des Imports in den
Leistungskennzahlen kann das gewünschte Stammdatenfeld dann unter “Mitarbeiter-Mapping” ausgewählt werden.
fromYear, fromMonth, fromDay, toYear, toMonth, toDay bezeichnen das Zeitintervall, für das ein Wert durch
die Abfrage ermittelt werden soll. Beide bezeichneten Tage sind noch Teil des Zeitintervalls; ein ganzer Monat wird dann
beispielsweise durch die Werte (2015, 1, 1, 2015, 1, 31) ausgedrückt.
Das Ergebnis der Abfrage muss zwei Spalten enthalten. Die erste Spalte enthält den Wert von leistungskennzahlwert_id
aus der oben beschriebenen temporären Tabelle. Die zweite Spalte enthält einen Zahlenwert mit dem ermittelten Wert
(Ganz-, Festkomma- oder Fließkommazahl).
Eine Abfrage für PostgreSQL kann beispielsweise wie folgt aussehen und könnte so in das Konfigurationsfeld “Abfrage” eingegeben werden:
SELECT nv.leistungskennzahlwert_id, ( SELECT COALESCE(SUM(sub.betrag), 0) FROM (SELECT a.betrag, make_date(a.year, a.month, a.day) AS datum FROM Auftraege a) sub WHERE sub.datum BETWEEN make_date(nv.vonJahr, nv.vonMonat, nv.vonTag) AND make_date(nv.bisJahr, nv.bisMonat, nv.bisTag))FROM #neededValues nv;Eine Abfrage für den Microsoft SQL Server kann beispielsweise wie folgt aussehen und könnte so in das Konfigurationsfeld “Abfrage” eingegeben werden:
SELECT nv.leistungskennzahlwert_id, ( SELECT COALESCE(SUM(sub.betrag), 0) FROM (SELECT a.betrag, DATEFROMPARTS(a.year, a.month, a.day) AS datum FROM Auftraege a) sub WHERE sub.datum BETWEEN DATEFROMPARTS(nv.vonJahr, nv.vonMonat, nv.vonTag) AND DATEFROMPARTS(nv.bisJahr, nv.bisMonat, nv.bisTag))FROM #neededValues nv;Export der Auszahlungsdaten
Abschnitt betitelt „Export der Auszahlungsdaten“Für den Export der Auszahlungen, die maXzie berechnet, kann eine CSV- oder eine Excel-Datei aus der Weboberfläche heruntergeladen werden. Die Standard-Exportdatei hat folgendes Format:
| Nachname | Vorname | Saldo vor Auszahlung | Empfohlene Auszahlung | Auszahlung | Währung | Datum |
|---|---|---|---|---|---|---|
| Zie | Max | 1000,00 | 800,00 | 800,00 | EUR | 2024-01-01 |
Das Format der Datei kann vom maXzie-Support angepasst werden.